The Parser/Data Dictionary (P/DD) is the heart of the control mechanism of IDIOMS, and consists of a set of processes and data structures (SQL tables). It resides on the host as a central resource, not a replicated one, because global control is needed for resource allocation, and a replicated directory structure is not strictly scalable, inasmuch as the size of each instance is proportional to the number of nodes.
The parser/data dictionary process consists of sub-processes, viz. parser, data dictionary, query optimiser/allocator. All of these are logically separate, although they interact closely. The Parser takes an MIS query in textual form, parses and validates it, and an internal representation is generated. Ale query optimiser/allocator requests information from the Data Dictionary, and uses this to generate the 'best' access plan [MURR91], considering the processing resource available, partitioning, and heuristics on previous hit rates of queries.
The basic required functions of the Data Dictionary (DD) are to:
In order to do this, a set of tables, which are an extension of SQL catalogue tables, are used.
The data dictionary contains a set of tables, which hold information on various aspects of the system. Although they are all integrated, for convenience we group them under a number of headings; SQL DDL catalogue, DSDL, Resource Control, Statistics. The latter three groups are known collectively as SQL Catalogue Extension tables. All these tables are based on SQL2 [ISO90], but implement only SQL version 1 (SQL1) with Integrity Enhancement [ISO89].
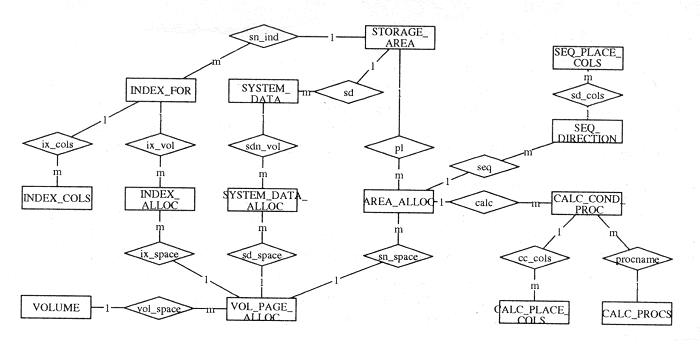
For any given database system, all the information that is specified in the DSDL is stored in the DSDL tables, and the schema definition is stored in the DDL tables. Statistics tables, and Resource Control tables are discussed in sections 4.4 and 4.5 respectively. Entity Relation (Chen) diagrams for DSDL and Resource Control tables (attributes are not shown) are given in figures 1 and 2. The DSDL tables link into the SQL DDL tables via a Foreign Key reference from STORAGE_AREA to TABLES. Note that although for convenience we have used the symbol # in some identifiers, strictly, this is not allowed in SQL2.
Figure 1. Entity relation diagram for DSDL tables
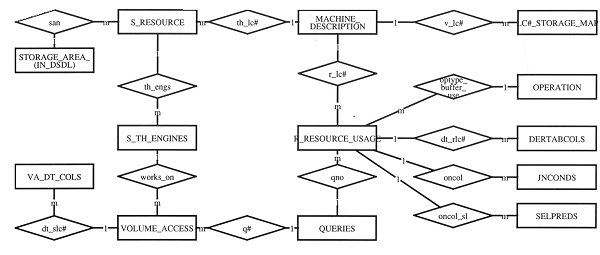
Figure 2. Entity relation diagram for Resource Control tables
Statistics tables store statistics on queries and on accesses to the database. In addition to aiding the optimiser to generate an access plan, statistics may also be used to aid longer term optimisations. For example, machine resource usage statistics can tell us if more relational processors are needed for the given number of disks available and the queries needing servicing.
Statistics on queries enable us to refine our heuristics for access plan determination. For example, if one column is predominant in selection predicates, this indicates that some access optimisation should be made on this column—perhaps partitioning, storage in physically sorted order, or in extreme cases, even an index. We envisage that a process could periodically scan the statistics tables, and generate appropriate messages to a database administrator.
Initial partitioning of data is based on an analysis of previous MIS queries on the application data, or expected MIS queries if no previous queries are available. Those columns which have selection predicates on them are candidate partitioning columns. It may be that these are never seen as part of the data returned, indeed, they may not even be initially projected from the base relation. Note how with this analysis, we do not need the concept of query type. Although the analysis takes place before the system is operational, this initial collection of statistics on MIS queries will be contained within the overall collection.
Statistics on the access patterns which arise can be compared with query statistics. Differences in patterns between the two indicate areas where changes to access methods/partitioning might be appropriate.
These aspects are areas of current research, and will be the subject of future publications.
The interconnection network that is used in a system is immaterial to the operation of the Resource Control tables, except that logically close resources should also be physically close (in terms of message hops needed to communicate). This means that our work can be generalised to other database machines which are based on dataflow concepts, and which use the shared-nothing architecture.
There are two types of sequences, intra-, and inter-query. SEQ# in the tables (see figure 3) refers to intra-query sequencing, whilst 0# itself gives an implicit order to the resource allocation between queries, assuming that all MIS queries have the same priority. SEQ# increases only if a resource is queued, and the number is specific to an instance of a resource.
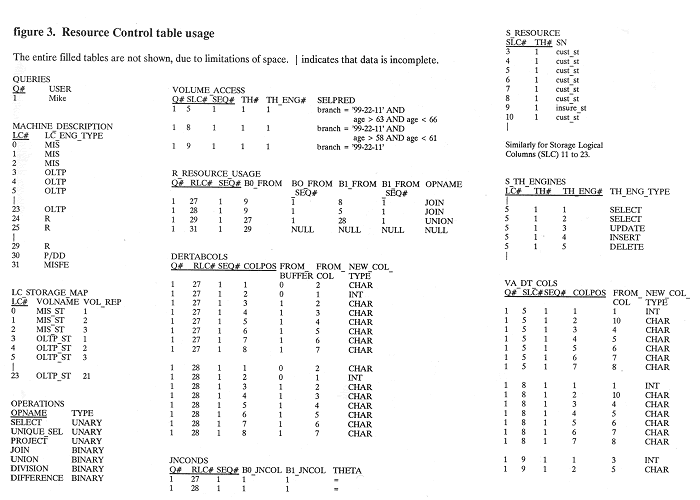
Figure 3. Resource Control table usage
Where a binary relational operation is followed (in the query tree) by Select or Project, both the operations are likely to be performed on the same processor. This does not go against the dataflow principles of our design, and there is a definite disadvantage (i.e. an extra communications cost) in performing the operations on separate processors.
Logical Columns (LC) are used in the tables merely as a convenient way of identifying processors, and they have no significance apart from this. Each storage processor, and each relational processor and associated buffers, is considered as a logical column. The output of a logical column is a derived table in SQL terms. The column definitions of a derived table (see DERTABCOLS) from a UNION, INTERSECT, or DIFFERENCE relational operation are replicas of the column definitions of the data entering input buffer BO.
Where a Select operation retrieves all tuples from disk, the predicate is indicated with an asterisk. This is in preference to using NULL, or an empty string, because it shows that the predicate is known. Additionally, it conforms to SQL notation.
MACHINE_DESCRIPTION defines the type of the Logical Columns (LC) of the machine.
QUERIES relates Query number (Q#) to user_id. Each query is given an internally generated identifier.
OPERATIONS is a list of (not necessarily purely relational) operations that are allowed, along with an indication of the arity of the operation.
R_RESOURCE_USAGE specifies the operations that occur on the Logical Columns that are defined as R. The input buffer usage is checked against the operation's arity.
DERTABCOLS (derived table columns) defines the structure of the output data stream of a relational processing Logical Column. The output data structure is derived from the input stream(s). Column NEW_COL_TYPE is needed here, since the domain of a derived column can be different from the domain(s) of its input column(s). For example, inputs may be two dates or times, and the output will be an interval—clearly, a domain change has taken place. In SQL2 it is possible to specify a domain change using the CAST operation.
VA_DT_COLS (volume_access derived table columns) defines the structure of the output data stream from a storage processor. A column to describe new column type is necessary here, because although the domain of a projected column does not change, its position in the derived table will probably be different from that of the base table.
JNCONDS (Join conditions) defines the condition and the (single) columns of the two input streams, on which the Join takes place.
SELPREDS (Select predicates) defines the predicates on which a relational select operation works. It is applicable only to Relational processing engines, not Selection engines, as these are dealt with by the table VOLUME_ACCESS.
S_RESOURCE relates Storage Name (i.e. the name associated with a data partition) to Table Handlers (TH), on each of the (storage) Logical Columns.
S_TH_ENGINES defines the available Table Handler engines, and their type, for each Table Handler.
VOLUME_ACCESS holds information on the Table Handler engine usage, and the selection predicate, if any, that is applied. The page location of the relevant Storage Name is held in the DSDL tables.
LC_STORAGE_MAP relates (storage) Logical Column to a physical volume. There is a FOREIGN KEY reference to the DSDL table VOLUME, which defines volumes.