This section states explicitly all the implementation decisions that were made during the detailed design of the author language functions, and the reasons for making them. It is envisaged that other developers will continue with the project, and therefore they will need to know this information.
As this chapter is written with developers in mind, many terms that are used will be meaningful only to people who have some familiarity with the C programming language. These terms are not explained in detail, since it is not the purpose of this chapter to introduce C, but rather, to explain how C is used in the functions.
To help ensure that the author language functions were written to do exactly what the user wanted, the User Manual was written prior to the internal design or coding of the functions. By doing this, functions would match user requirements, rather than the requirements being altered to match what could be implemented easily [Weiss, 1984].
At this stage of development, the name PAL (Prototype Authoring Language) was given to the suite of authoring functions.
A highly modular approach to the design of procedures and functions has been used. The reasons for taking this course of action have been expounded by many writers [Allworth & Zobel 1987, Connor 1985], so I intend to give no more than a brief gloss to the topic.
Two terms that frequently appear are coupling and cohesion. Allworth and Zobel write in the context of real-time software design, and their comments are relevant, and very succinct. 'Coupling is a relative. measure of the strength and complexity of module interconnection. Ideally, there should be a minimum amount of coupling between modules. it should be possible to remove a module from the system and replace it with a new modified or alternative module without affecting any other module or module interconnections. If this is so, then both the cause of easier software project management and the ideal of easy maintenance are furthered. By reducing inter-module connections and defining modules that are, as far as possible, free-standing, the designer stands a better chance of being able to replace modules with minimum disruption at a later date'.
Various types of coupling have been identified, some of which are more undesirable than others, but I do not intend to discuss these. One point to note is that there has to be some coupling, otherwise there could be no interaction at all!
Cohesion describes the internal structure of a module. From low to high cohesion we have coincidental, logical, temporal, procedural (or sequential), communicational, and functional cohesion. The first three of these are not particularly desirable, whereas the others are [Allworth & Zobel 1987]. In the design of the procedures which are used in the author language routines, I have followed these guidelines.
Constraint handling was not a major difficulty; most of the limits imposed were set in the requirements stage of the development of the author language functions, although a few were hardware dependent. There is also a set of what might be termed 'semantic constraints'—in other words, for a given program state, some (attempted) operations are nonsensical.
The length of the input string which is obtained by the getanswer function is limited to 80 characters.
The number of options in the multiple choice functions is between two and six inclusive. Each option can be no longer than one screen line.
The maximum number of words that can be dealt with in the function matchany is nine.
The header and message areas are limited to one line each.
Physical limitations of the hardware used for the development of the functions restricted the number of screen rows available for display to a maximum of 25, and screen columns to 80.
These are called Author Errors in the preceding chapters. An example of an Author Error is the function call:
clearbetween(10,50);
which indicates that the main display area should be cleared between rows 10 and 50. Since there are twenty-three screen lines available for the main display (on a twenty-five line screen), this function call is invalid.
The author language routines were developed on an Olivetti M24 (640Kb internal memory), with a monochrome screen (25x80), one 10MB hard disk, and one 360 Kbyte floppy disk drive.
Any machine that can run Microsoft QuickC (ie an IBM PC or compatible) should be capable of being used for the further development of the functions. The requirements are:
An IBM PC or compatible machine, MS-DOS version 2.1 or later.
One hard disk and one floppy disk drive, or two floppy disk drives.
At least 448 Kilobytes of available memory (512K is recommended).
Microsoft QuickC version 2.0 or later.
The C programming language is perhaps not as suited to string matching functions as are languages such as Lisp and Prolog; however it does have certain other advantages, which influenced the company's decision to use this language.
The language is becoming increasingly important (ie well known and much used) in commercial/industrial applications, and the company therefore are interested in testing its potential for their particular application.
Also, it can be used in the Unix environment, and the company thinks that this might have commercial implications in the future.
Since the question of which language to use had been decided by the company, the only question to resolve was which C implementation to use. (The company would then purchase this). Although the company is interested in the Unix environment, they currently use MS-DOS. Therefore, the implementation that was chosen was one which could be used with MS-DOS. Transfer to a Unix environment at a later date should be possible if only standard ANSI C is used (but see 6.4.1).
Features that were most relevant to the project were good string handling ability, along with fast execution time for this (rather than good arithmetic capability, for example), and it was on this basis that the final selection was made.
The implementations considered were Aztec C86, C86Plus, DeSmet DC88, ECO-88, High C, Lattice C, Let's C, Living C Plus, Microsoft C v5.0/v5.1, Mix C, Power C Works, Microsoft QuickC, Turbo C, and Zortech C v2.0 [PC User No 79, PC Magazine Dec 1988, Buyer's Guide June 1988, PC Plus July 1988, PC Plus Dec 1988].
Microsoft's QuickC was selected as the most suitable implementation with which to work. Tests [PC Magazine, Dec 1988] show that it has one of the fastest execution times for string handling routines, without compromising on executable code size. Other tests [PC User No 79] suggest that Turbo C has quite an advantage, both in speed and executable code size, but as the operations tested were limited in range, the tests cannot be considered valid.
During the detailed design stage, a number of problems arose due to the way in which QuickC works. Some of these could perhaps be resolved by a more experienced programmer, but I was unable to do so.
The original project requirements called for a multiple choice function which could accept an arbitrary number of options. Although this is possible using va_arg and associated va macros, there is one drawback; the function needs to be able to determine when the final argument has been reached, or alternatively, it needs to know how many arguments to expect.
Example programs supplied with the implementation language use the former method. For example, vararg.c demonstrates the calculation of the average of a list of integers. Any number of positive integers may be input, but the end of the list is shown by a sentinel value of -1.
This is not a suitable method for the purposes of the multiple choice functions—although if, for example, an empty string were defined as ENDLIST, it would not be too messy. An mc function call would then be, for example:
mc( <stem>, <optl>, <opt2>, <opt3>, <opt4>, ENDLIST );
A neater method (which fortuitously is preferred by the company!) is to have a set of multiple choice functions, each one of which takes only a fixed number of options. Thus, we have mc2, mc3, etc. This is only the surface view, however. There is one main multiple choice function (called mc), which deals with the processing of all of these. Each function passes its parameters to mc, along with an integer which tells mc how many option strings to expect.
Unfortunately neither this method, nor the first, can be used when passing a match parameter list to the model/ answer matching functions, so that rather than being able to omit the match parameters if no change to the default is required, they always have to be stated, even if only to say that no change is required.
Space is reserved for every variable at run-time, and each answer variable must be able to hold 80 characters (in the prototype). Therefore, even if only twelve variables were declared, nearly one kilobyte of memory would be used, whether or not any answers were assigned to these variables.
In the requirements section (4A.2) it was suggested that the getting of an answer, its comparison with a model, and the action to be taken due to the result of this comparison, could be in separate sections of a program if an author so wishes. At a very late stage in the development of the functions, when the problem mentioned above was discussed with authors at Dean Associates, the conclusion was reached that the option of getting and testing answers in separate sections of a program was really an unnecessary luxury that would not greatly enhance the overall package. The use of just one ANSWER variable would suffice; it could be tested for comparison with the model at any time prior to calling the getanswer function again. The results would be available throughout the remainder of the program if an author wishes, since for all practical purposes there is no limit to the number of MATCHRES variables.
Version 1.0 of PAL has not been changed to reflect this new viewpoint; there is the suggestion, however, that not more than ten ANSWER variables are declared, in order that stack overflow problems do not arise.
Future versions of PAL could be modified, so that only one ANSWER variable is available to the author. This could be part of the global state, and hence would not have to be declared by authors. Additionally, the function calls to getanswer, and the comparison functions would be simplified. The answer would not have to be specified, as it would be the 'current answer', that is, the answer most recently obtained. Function calls would then be, for example:
getanswer( <length> );
mres = alphamatch( <model>, <match parameters> );
mres2 = findword( <model>, <match parameters> );
mres = matchany( <number>, <model>, <match parameters> );
The original requirements stated that getanswer should have the following form:
getanswer( <length> )
where <length> was an integer between one and the maximum answer length. The implication was that it would be used in the following manner:
answer_1 = getanswer( 25 );
Because C does not return strings, but only pointers (to a string in this case), this is inherently unsafe, since there is no way (as it stands) that the function can change answer_1 globally. The function could get an answer, and return a pointer, but when the function is exited, it is possible, though not definite, that at some time in the future, the area in memory to which answer_1 is pointing could be overwritten.
The way round this in version 1.0 of PAL, is to make answer_1 a parameter (in the form of a pointer) to the function. The area in memory to which answer_1 refers is external to the function itself, so although answer_1 can be changed by the function, when the function is exited, there is no danger of the memory area being overwritten. The function call is now, for example:
getanswer( answer_1, 25 );
However, if the considerations regarding the maximum number of ANSWER variables are taken into account, this change to the getanswer function becomes irrelevant, since there would be only one current answer variable, which would not have to be specified in any case.
Authors must declare all the variables that they use.
MATCHRES is equivalent to the type int in the C language, and is used to hold the values returned from the model/ answer (matching) functions.
ANSWER is equivalent to char in the C language. Each ANSWER variable must be initialised (made to point somewhere), and to do this, a keyword, SET, has been defined in authprog as:
[80] = " "
An ANSWER variable is initialised thus:
ANSWER variable_name SET;
This is the same as writing:
char variable_name [80] = " " ;
An implementation can contain features which have been introduced solely from the representation, and which have nothing to do with the specification [Thomas, Robinson, Emms, 1988].
Although as far as possible, the functions have followed the ADT specification (chapter 5), some changes have been necessary. These have already been dealt with, so will only be mentioned in passing in this section. In addition to these changes, some of the functions are incomplete, inasmuch as they do not do all that is required. Future versions of PAL should rectify this situation.
One general comment on the implementation is that it does not use ANSI compatible C. Microsoft QuickC contains many useful commands, and these have been used where appropriate. If ANSI compatibility becomes necessary, then some sections of code will need to be altered.
The source code file structure is as follows:
/* PALFUN.C */
include all necessary h files
global definitions
define windows
enumerated type definitions
structure definitions
function declarations
function definitions
Each function (in most cases) is in a separate include file,
except for write (it is called text, explanation later),
which follows the final include file.
#include "filename_1.fun"
#include "filename_2.fun" etc
main()
{ /* sets up global state, and then calls authprog */ }
An author's code is contained in the function authprog. The function declaration for this, along with defined constants (ie the reserved words, such as OPT1, NOANS, etc), are contained in the file hidden.inc, which is put into the include directory, when the system is initialised for PAL usage (User Manual, section 2.2).
When an author writes a program, the first line of his/her code must be:
#include <hidden.inc>
Before a PAL program can be compiled, a program list must be set to contain palfun.obj, and the author's file. The procedure for doing this is explained in the User Manual.
Note that palfun is supplied as palfun.obj, which means that only the code of authprog need be compiled, and then linked to palfun.obj.
Internal coding changes can be made to any of the functions, without affecting the way in which the overall system works. However, if this is done, recompilation of all the functions is necessary.
The following section lists each function that does not follow the specification, along with the omissions or changes that have been made in the implementation.
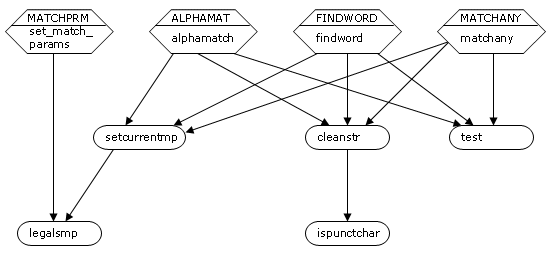
As a general rule, functions are not used recursively, and PAL authoring functions do not call each other. One exception to this is the function message, which is used by many of the functions to display a message. On the final page of this chapter is a diagram showing the internal function calls of the PAL model/answer matching functions.
author_error has not been implemented. Author errors are coded into the functions where appropriate. When an author error occurs, a message is generated, but the program does not terminate. This should be rectified.
authprog is not defined either formally or informally. it is used so that the PAL functions, and author's code can be compiled separately.
cleanstr in the implementation, is equivalent to
removeblanks(removepunct(upper(string)))
in the ADT specification. It is also used where only
removepunct(upper(string)) is required.
compare and compare_without_assistant in the ADT specification are incorporated into test in the implementation. Wild cards and wild characters are not be dealt with in version 1.0 of PAL.
The conditions for acceptance of an error (applicable only to the function compare) are illustrated below. In particular, note the examples with wild cards (denoted by an asterisk), where certain types of error are not interpreted as we might initially expect. A question mark denotes the wild character.
| Model | Answer | Error |
|---|---|---|
| example | example | none |
| example | exampel | transposition |
| example | exampl | omission |
| example | examplle | insertion |
| example | exemple | substitution |
| Model | Answer | Error |
|---|---|---|
| ex?mple | exzmple | none |
| ex?mple | eyxmple | transposition |
| ex?mple | exmple | omission |
| ex?mple | exyample | insertion |
| ex?mple | exyzple | substitution |
Leading (eg ?sign) and trailing (eg sign?) wild characters are dealt with in a similar manner to the examples shown above.
| Model | Answer | Error |
|---|---|---|
| *consider | re-consider | none |
| *consider | re-ocnsider | transposition |
| *consider | reconsider | omission |
| *consider | re-cconsider | none (insertion.-->.none) |
| *consider | re-xconsider | none (insertion.-->.none) |
| *consider | re-vonsider | substitution --> omission |
| *consider | reconsider | omission |
| *consider | rec-consider | none |
To aid clarity, as an example, a hyphen is used. This, and anything preceding it, would be ignored by the functions which compare a model and an answer.
| Model | Answer | Error |
|---|---|---|
| fraction* | fraction | none |
| fraction* | fractional | none (insertion --> none) |
| fraction* | fractioanl | transposition --> omission |
| fraction* | fractioal | omission |
| fraction* | fractiobal | substitution.--> omission |
Insertion cannot occur on a leading or trailing wildcard boundary—it is analysed as part of the answer which corresponds to the wildcard in the model.
Substitution, if it occurs an a leading or trailing wildcard boundary is analysed as an omission.
Model answer strings which have a wildcard which is in a medial position (eg re*ation) are dealt with using either the leading, or the trailing models shown above, or both, as is appropriate for the error involved.
createprogram is equivalent to the coding that precedes authprog in main(), and the global variables that are defined.
There is no checking that the window parameters are sensible; the result of using the functions write, header, and message are undefined if nonsensical windows parameters are used.
The model/answer match functions return a string of one character ( "?" in PAL version 1.0) if the Fl (help) key is pressed. It would be better to define a global constant (preferably a non-keyboard character) say HELPSTRING, which could be used in all these functions.
getanswer has in addition to the problems noted regarding the format of the function, a minor difficulty with the length of the answer. Currently this function accepts answers of maximum length 79 characters, not 80 as required. The reason for this is that the original code was not written to deal with the anomalous last character, where the cursor should not move to the next line. Lack of time prevented correction of this, so the problem was prevented by the simple expedient of reducing the maximum answer length.
header The specification calls for a check to ensure that the header string could not occupy more than one screen line (ie no newline control characters are embedded in the header string). Although this is not done, it is not a major problem; scrolling will occur and only the final line of the message will be seen. However, as with all other inconsistencies, omissions, etc, it should be rectified in future versions of PAL.
legalscmp, which is not defined formally, has not been implemented; in its place legalsmp is used as a temporary stopgap.
legalsmp, which is not defined formally, is only partially functioning, in that duplicate match parameters are not prevented.
matchesin in the ADT specification is incorporated into matchany in the implementation.
match_to_next_wild has not been implemented.
mc2, mc3, mc4, mc5, mc6 all work in a similar fashion. There is a function, mc, which is at the heart of all of these multiple choice functions. As an example consider mc3.
mres = mc3( <stem>, <optl>, <opt2>, <opt3> );
All mc3 does is to call the function mc, passing to it, in addition to the stem and options, an integer (3) which states how many options to expect. Refer to section 6.3.2 for an explanation of why the original requirements could not be complied with.
one problem that has not been overcome with the multiple choice functions is that if the number of options is less than the number that is expected, a system error occurs.
message as for header.
removeblanks in the ADT specification is incorporated into the cleanstr function in the implementation.
removepunct in the ADT specification is incorporated into the cleanstr function in the implementation.
skiptill has not been implemented.
upper is incorporated into the cleanstr function in the implementation.
write, which was not formally defined, had to be called by another name (text was used), and then redefined in authprog, because the implementation language does not allow the use of this word, due to confusion with write.asm.
PAL functions are supplied to authors in a pre-compiled form. In order to optimise the object code size, and hence the author's final executable file, the compilation process should be done using qcl, rather than from the C editor. The /Ox qcl command line option should be used to maximise optimisation (see QuickC Toolkit, chapter 4.3, QCL Options).
The small memory model should be used—it need not be specified, as it is the default.
A stack size of 2k is ample for the pre-compiled functions, so again, the default may be used, and need not be specified. Note that when a PAL program is compiled, the stack size needed is slightly more than the default of 2K. Experimentation has shown that a value of 3K appears to be suitable, as long as no more than ten ANSWER variables are used.
Authors compile and link their programs from the QuickC editor, and prior to the first compilation/linking session, they must set the stack size to 3K, using Make, in the Options menu, in order to comply with the requirements detailed above. The procedure is explained in detail in the PAL User Manual, section 2.2, System Initialisation.
Rather than authors changing the system defaults, it would be far better if the memory needed by authors' programs could be reserved for them, in the pre-compiled object code, but so far no method of doing this has come to light.
Map of function calls for PAL model/answer comparison functions.
Large angular boxes show PAL functions. The name at the top shows the file (without .fun extension) in which the function source code can be found.
Small ovals represent functions internal to the PAL authoring system.
Main, which calls authprog, is not shown.
Preface | Contents | 1 Introduction | 2 Review | 3 Req. analysis | 4 Req. documents | 5 Specification | 6 Design | 7 Verification | 8 Discussion | 9 PAL manual | Appendix A | Appendix B | Appendix C | Glossary | References | Index