This is the end of first-year report that summarises the work that has been done since May 1990, on the project entitled 'Control of a Transputer Based Database Machine'.
The research project is a SERC/CASE collaboration with Hewlett-Packard, the aim of which is "to investigate the data dictionary and control requirements of a loosely-coupled multi-processor database machine".
Research is to be carried out within the framework of the proposed DRAT machine [KERR88], and Kerridge's Data Storage Description Language (DSDL) [KERR91b], which are explained in the following sections.
Other researchers are undertaking work related to the DRAT machine, and where appropriate, liaison with them will take place.
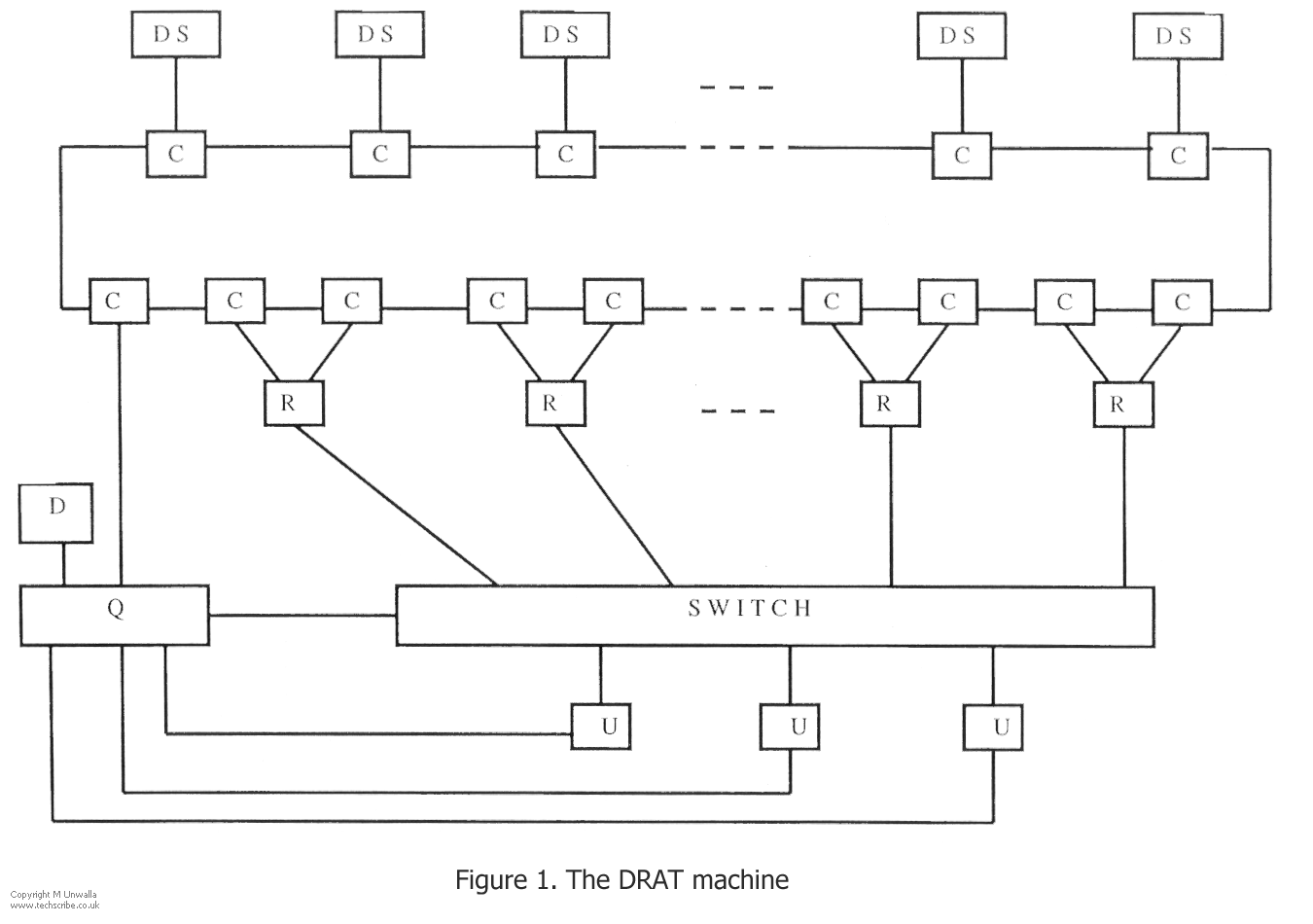
DRAT (Dynamically Reconfigurable Array of Transputers), a transputer based database machine, was proposed by Kerridge [KERR88]. In the light of new knowledge, the original architecture has been improved [KERR90] (fig 1), and is outlined below.
Memory is distributed, and all communications take place by message-passing. The DRAT machine has decentralised control, messages themselves contain destination routing information.
User Processors (U) can be a single user workstation, gateway to a network, or mainframe or mini that has a transputer link. They are connected to the Query decomposition processor (Q), which decomposes and optimises queries.
The Data Dictionary (D) functions as a repository of metadata, and also has a control role in conjunction with query decomposition processes (Q). The dictionary determines which processes need to be activated, and allocates processors to do this.
Relational processors (R) do the main query processing tasks. output is directed to the switch, which enables any R to be connected to any user processor (U), or data can be recycled, thus enabling nested operations. (Buffers and 1/0 processors associated with R processors are not shown).
DS processors deal with all aspects of data storage. C processors form a communications ring.
The IDIOMS (Intelligent Decision Making in Online Management Systems) version of DRAT [KERR91a] serves two functions, namely On Line Transaction Processing (OLTP) and Management Information Services (MIS). Some of the relational processors and data storage elements will be dedicated to OLTP, and others to MIS. Any MIS query can access, but not change, OLTP data. The OLTP sub-system knows nothing of the IDIOMS MIS sub-system.
The aim of DRAT is to support a database of 250 GB, and to achieve 5000 transactions per second (TPS), which compares favourably with other systems. For example, Tandem's (distributed) database system used in conjunction with their NonStop SQL has been benchmarked at 200 TPS, and "disposes of the myth that relational systems are inherently slow" [TAND89]. Thus it can be seen that DRAT has much to offer.
The word 'reconfigurable' has two meanings in the literature. According to Lee and Smitley, "an inter-connection network is called reconfigurable if its topology can be changed between different algorithm executions" [LEE88]. This is known as a reconfigurable topology architecture, and it is possible to allow multiple independent tasks to run separately. The meaning with which it is used in the DRAT architecture is that which Duncan uses when he describes systolic arrays, namely that various algorithms (in our case processes) can be assigned to array elements (or processors in DRAT) [DUNC90]. To summarize, there is processor reconfiguration, and processor-process mapping reconfiguration; DRAT uses the latter.
The architecture of DRAT is novel; to date the author has been unable to find other work which suggests that a ring of transputers arranged similarly to DRAT is a possible option for a database machine. The two other transputer based database machine architectures noted in the literature are discussed in section 2.1.4. There is one reference to a "Dynamically reconfigurable transputer based architecture" [DENG88]. The paper has been unobtainable to date, so no comments can be made, except that neither the type of reconfigurability, nor the application domain is outlined in the abstract.
An SQL database schema defines data, but says nothing of how the data is to be stored. Storage of data can be defined using a Storage Schema, this storage schema being produced by means of a Data Storage Description Language (DSDL).
Zorner [ZORN87] defines two basic types of data placement within a storage schema: gross, and fine. Gross placement is the partitioning of tables into what is known as storage areas. This partitioning may be a simple 1:1 mapping of an SQL table to a storage area, or the table may be partitioned into many storage areas according to the value (s) of some fields, thus allowing data to be split according to its value (and implicitly, its usage). Fine partitioning deals with the placement of data within pages of each storage area, and allows for the optimisation of different SQL operations.
Kerridge's DSDL [KERR91b] will be used in this research. It defines three fine placement strategies, namely Calc, Sequential, and Serial. Calc is a hash based placement. Sequential places storage records in ascending or descending order within a range of pages. Serial is simply an unordered storage that places the record in the next available location.
Zorner's DSDL does not define how storage areas are mapped to physical devices. Kerridge improves on this, by specifying volumes, and the mapping of storage areas to these, thus allowing a Database Administrator to allocate data to physically different storage media, depending upon the type of data and/or usage. Archiving is explicitly catered for, by allowing infrequently used data to be stored on relatively slow high volume storage devices, or even by deletion of data.
An aspect of Zorner's DSDL that is not currently incorporated into Kerridge's DSDL is version control. This does not mean that a storage schema cannot be changed, but rather, that at any one time all data will be stored under only one storage schema (version). As a result of this, if a new storage schema is desired, the database will be off-line during the re-organisation.
Both DSDLs allow the definition of indices, which can be used to increase the speed of access to data items.
Contents | 1 Introduction | 2 Review | 3 Research aims | 4 Program | 5 Work | References | Appendix A | Appendix B | Appendix C