The purpose of this chapter is to describe the applicability of previous work on database machine (DBM) architecture, Distributed Databases (DDB) , and Data Dictionaries (DD) , to the DRAT architecture. Although it is assumed that the reader is familiar with the basic concepts of relational databases, parallel processing, and Flynn's taxonomy, some definitions are given, in order that no misapprehensions may arise.
Traditional general purpose computers are better suited to numerical applications than to the kind of tasks required by the users of databases, which are qualitatively different. (There is no suggestion here that faster 'number-crunchers' are not needed).
One problem with using a traditional architecture is that of speed as perceived by the user (if users were satisfied with performance there would be little incentive for developing faster machines). Langdon stated, "programs running on the central processor tend to be the bottleneck to system throughput. The database machine (DBM) is the result of an architectural approach which distributes processing power closer to the devices on which data are stored. Another impetus for the approach is due to LSI (sic) technology. LSI has reduced the cost for decentralised memory and logic" [LANG79].
Other factors such as reliability, security, database storage, modularity [YAO87], price-performance ratio, and ease of programming give added impetus for the development of special purpose database machines.
To overcome such problems, various database (DB) machines have been proposed, and some have been built. A few machines, such as the Britten Lee IDM series, and Teradata DBC/1012 are commercially available.
As an aside, there is a sound philosophical basis for database machines. In most situations tools are designed for specific purposes; computers need not be an exception (although, of course, in some cases we may want an all-purpose do-everything machine) [see LITW84].
"A database machine can be defined as a specialised software/hardware configuration designed to manage a database system" [YA087] Essentially, two forms of DB machine exist; backends, and special purpose database machines. A backend database machine offloads database activity onto a purpose built add-on unit. Results are returned to the host machines [YA087]. Special purpose database machines, as their name indicates, are just that; machines built to support (primarily) database operations. DRAT is designed as a special purpose database machine The next section describes the major approaches to building data base machines, based around Su's functional classification to group them (see Appendix A, "A note on taxonomy").
This section is brief, as it is not intended to be a tutorial, merely an overview. Taxonomy per se is not relevant to the research program, but useful as a framework around which to discuss concepts.
Su's classification is not tidy. The overall functionality of intelligent secondary storage devices, and database filters is identical. According to Su, both use special hardware, but in different locations. No mention is made of purely software approaches which use standard components to achieve the required functionality, which is the DRAT approach. Additionally, DRAT has both distribution and replication of functions (discussed below), which does not fit neatly into Su's classification.
Traditional secondary storage devices have no processing power, so data has to be transferred to main memory before it can be processed. This can be a bottleneck, which intelligent secondary storage devices try to overcome, by selecting only relevant data to be sent to the main memory.
Cellular-logic devices consist of a set of cells, each of which is composed of memory and a processor. For each track of a rotating (used in a very loose sense) memory device (disk, drum, CCD, magnetic bubble memory) there is a cell. If the whole data base is stored on a set of these, then it can be searched in one revolution. Data is accessed by content, rather than address. Examples of machines built around this idea are CASSM and RAP.
Logic-per-head is a version of cellular logic that uses intelligent moving-head disks, rather than fixed head disks.
Logic-per-track is a more restricted form of cellular logic inasmuch as it is restricted to devices built around disk tracks.
These try to achieve the functionality of intelligent secondary storage devices, but without the need for developing new storage devices. A database filter consists of a regular secondary storage controller (which is likely to use indexing for access by address), and a special purpose hardware unit to perform the data filtering task. CAFS and VERSO are examples of machines that use this principle.
Su categorises multiprocessor systems under two headings: systems with replication of functions, and those with distribution of functions.
In systems with replication of functions, all the database management functions are replicated over a number of processors, and data is sent to these to be processed in parallel Distribution of functions means that processors are tailored to perform one (or just a few) specialised tasks. Data then has to be distributed to a specific processor for a given operation to be performed Many multiprocessor DB computers have been designed, and a lesser number of these built. Some are described in section 2.1.4.
Associative memory allows data to be retrieved by its content, rather than by using data location pointers. Also, rather than sequentially searching memory locations, as is the traditional approach, associative devices can be built to search memory words or bits simultaneously, thus reducing search time.
Most database applications to date deal with 'formatted data', that is, data which is of a highly structured nature, and which fits into fixed-format fields. Text processors are designed to deal with 'unformated' data (eg plain text). Further discussion is not relevant to this report.
This section reviews a number of recent multiprocessor database computer designs, and compares them to DRAT.
Transputers appear natural candidates for use in multiprocessing database environments. Each relational process in a logical query specification can be mapped to a single transputer, and thus the physical computation can follow the logical (optimised) query. The basis of the current research, the DRAT machine, has been described in chapter 1. Two other transputer based database architectures noted in the literature are described later.
Takahashi and Nakashima [TAKA87] describe a database machine built around a binary tree of processors. Horizontal fragments of relations are distributed to processing elements (PE), queries are broadcast to all PEs, and processed concurrently. Thus this machine has a replication of functions, and it can process only one query at a time. Although the design is radically different from DRAT, it is interesting to note that the authors suggest that the most promising form of data distribution is horizontal partitioning, which is what we have in DRAT.
DRAT could be described as "a relational database machine organisation for parallel pipelined query execution". There is a paper with this title [HIRA86] that naturally arouses interest. A DB machine, at first sight not unlike the logical design of DRAT, is proposed. There are a number of processing modules, connected to each other by buffers, and an interconnection network. Processing modules execute relational operations, except selection, which can take place on the secondary storage devices. A pipeline of relational operations can be set up. Multiple queries can be simultaneously satisfied.
Here the similarity ends. The storage devices (only one logical device is shown on the authors' diagram) are connected to the processing module interconnection network by means of a bus. The processing module interconnection network is constructed from 2x2 switching elements in a multistage fashion (MIN). Compare this to DRAT's ring, which combines the relational processor interconnection, and data storage to relational processor interconnection. Finally, the processing modules themselves are special purpose dedicated hardware units.
It is gratifying to note that the basic soundness of the design of DRAT (ie mapping each process of a query tree to a physical processor) has been supported by others, although they choose a very different approach in the implementation of their machine.
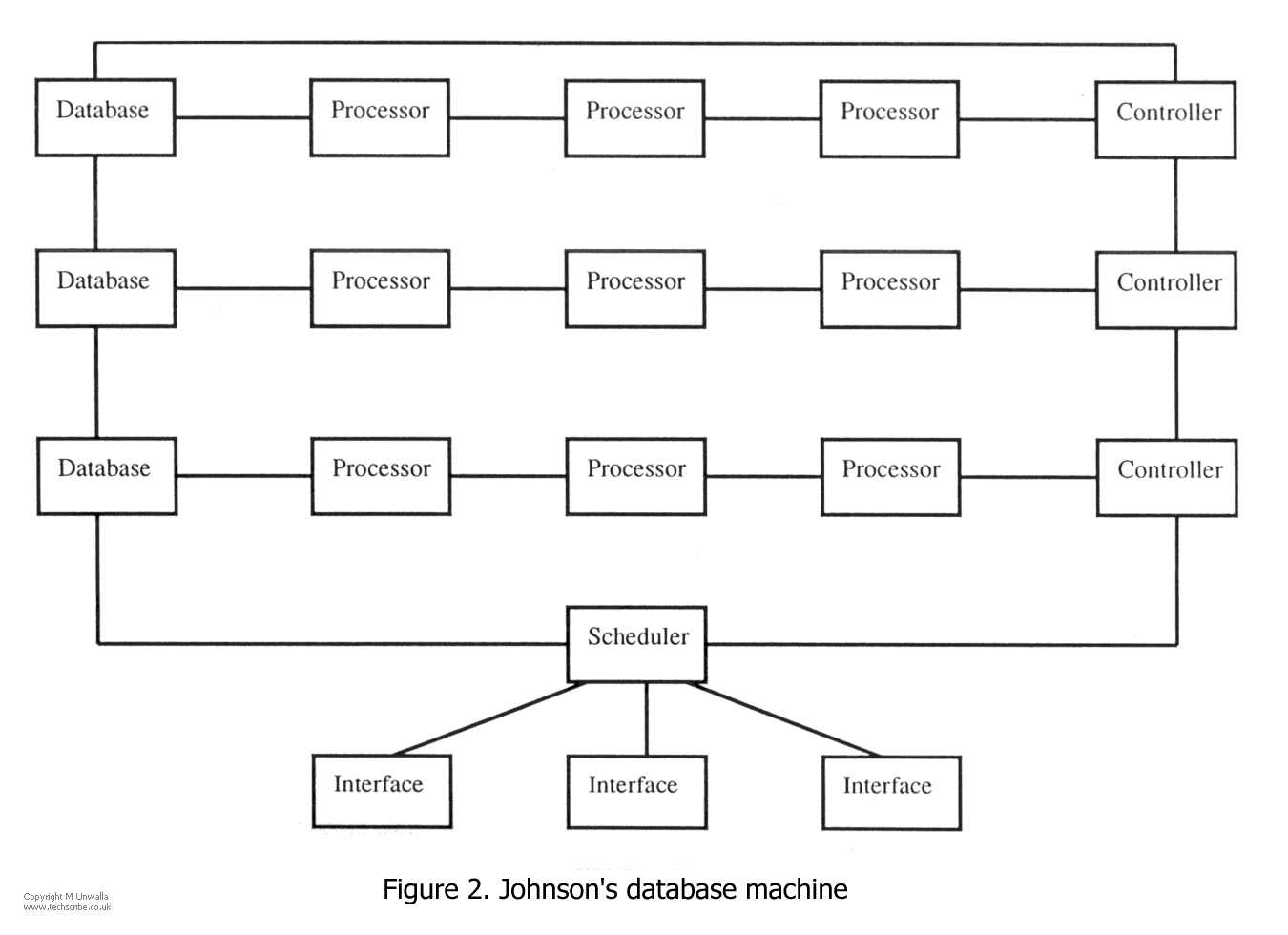
The object of Johnson's research [JOHN90] is to develop a high speed RDBMS, based on transputers, with a target on temporal/ spatial databases.
Each linked set of Database, Processors, and Controller is called a node, and the overall design can be considered as a distributed system composed of a number of nodes connected in a ring (fig 2). The Database manages the local database, and the Controller deals with the control and monitoring aspects. Allocation of work is through the scheduler, which receives transactions from Interfaces.
The system is accessed through SQL interfaces, which parses the SQL, and converts it into what the authors call "tasks", which appear to be (although this is not explicitly stated) equivalent to the operations that are defined on the nodes of a parse tree. The system allows a pipeline of tasks to operate.
The scheduler receives tasks, which are added to a list of other current tasks. Tasks are allocated to nodes depending on the location of relations, and the workload of each node. Nodes operate only on local data, although results can be sent to any other node.
Nodes operate autonomously. The controller receives a task from the scheduler, and allocates processors to that task. The database supplies data that is to be processed.
The database manages relations held at a node. These are chained together in 1K pages, and held in RAM. There is no partitioning (although the authors say this may be developed).
The reader can see that the ring structure of the design is radically different from that of DRAT.
An apparent limitation of the design is that relations can only be processed (initially) by processors on the node in which they reside. This could lead to bottleneck conditions if many queries referred to the same relation. This is in contrast to DRAT, where relations can be sent to any R processor.
The application domain of the system is not the same as that of DRAT, and one may assume that the target DB size is considerably smaller, since the design calls for all relations to be held in RAM (although the authors envisage this as being a cache for discs).
Grigoras' design [GRIG90] is shown in figure 3. The machine is designed to optimise Joins. A hash algorithm is used to partition relations into disjoint buckets, so that all tuples with the same join attribute value(s) are in the same bucket. Thus the join of two large relations can be reduced to the joins of many smaller buckets, which can take place on a number of processors.
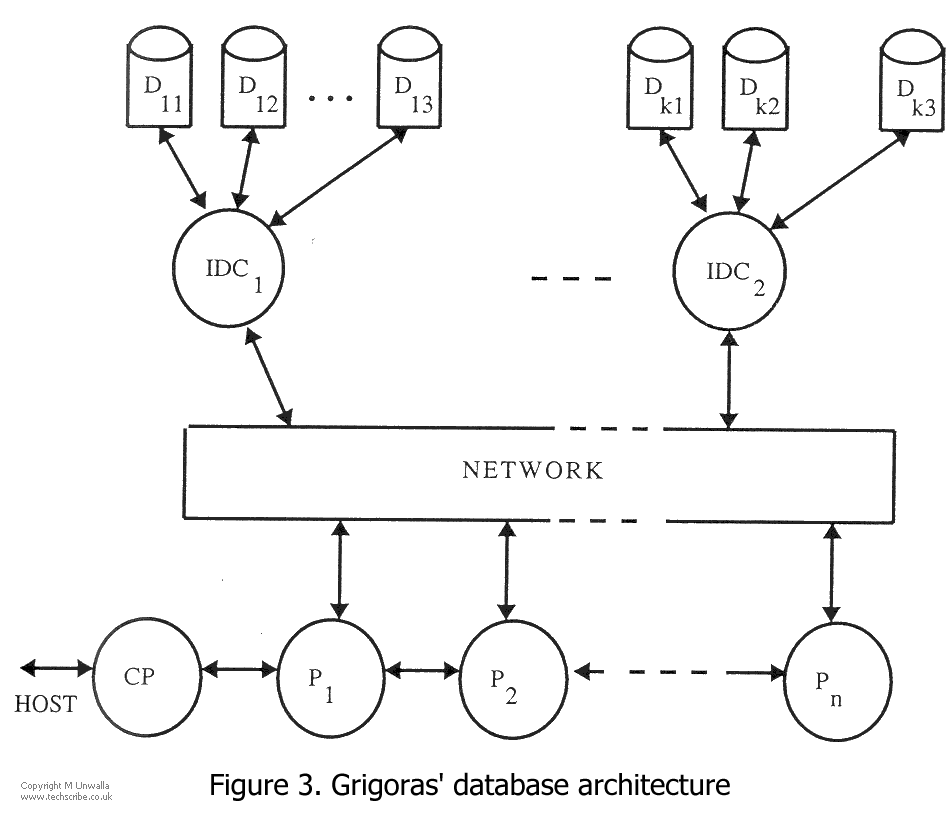
The controller processor allocates buckets to P (relational processing) processors on a 1:1 mapping. Tuples from disks are sent to the P processors (also known as servers). Each server runs a number of sub-processes. Servers are connected in a linear array, with the controller processor being at one end.
Tuples, where appropriate, may have relational selection and projection operations applied to them fore they are processed by the Hash Function processor. If a tuple received by P does not belong in the bucket associated with P, then it is routed to the correct P processor by the mailbox process, where it is buffered prior to join.
Grigoras addresses a different problem from that dealt with by DRAT in that he has designed a machine which answers only a single query at any one time. The machine itself is optimised for the join operation, since that is the most time consuming relational operation. The architecture has been designed on the premise that a hash algorithm will be used, and in fact, can not work with other join algorithms.
No consideration is given to data placement, and large queries with multiple joins are not discussed in the paper.
Optimal use of transputers is not made in the design. Each server deals with the join of buckets from two relations. As has been mentioned, prior to join, tuples may have select and project operations performed on them. Clearly, this could lead to a bottleneck, as the selection and projection operations for buckets from different relations must proceed in sequence on any one server.
Another apparent defect of the design is that each disc controller is connected to many discs, which could lead to access bottlenecks.
Grigoras concludes that if the number of servers becomes too large, then the server communications topology could be modified to a ring structure (cf DRAT). The distance that messages have to travel would be reduced, at the expense of a slightly more complicated routing process. Additionally, a ring of servers would allow a degree of fault tolerance.
Much early work on database machines attempted to address problems through the use of specialised hardware solutions, in contrast to recent work which tends to favour the use of commercially available components. We could say that specialised hardware solutions are physical implementations of database machine concepts (eg RAP), whereas the use of standard components leads to, in effect, a logical implementation (by means of software) of DB concepts (eg DRAT). In the short term, the latter approach is more likely to lead to commercially viable products; there need not be any conflict with longer term developments of hardware based solutions.
Loosely using Su's functional classification, we can say that DRAT is a multiprocessor database machine with both distribution and replication of functions (see appendix A) which uses software implemented database filtering on the storage elements.
A "distributed database implies several computers, each one with a DBMS managing data stored on attached permanent storage devices; a general or local network…; and some facilities to manage data across the network" [ESCU87].
According to Esculier, the major criteria to consider in a distributed database is the transparency to the user of the following: data location; multi-processors; data replication; heterogeneity [ESCU87]. In Deen [DEEN84], outlined below, these roughly equate to user facility; multi-level controls; privacy, integrity, reliability; heterogeneity.
A distributed O/S is needed to control distributed execution. Transaction atomicity needs to be guaranteed, and concurrency control, and recovery mechanisms are needed.
Users should be able to treat the DDB as a single database; for processing efficiency it is often desirable to fragment data and to distribute and replicate them over the nodes The following overview of distributed data allocation (ie partitioning, replication, and placement) strategies is based on Hevner and Rao's recent work [HEVN88]. Four design decisions are involved - data partitioning, placement, replication, and dynamic allocation.
There are two forms of partitioning, vertical and horizontal. Partitions may be placed on separate storage devices. Vertical partitioning splits a file/relation such that some attributes appear in one partition, and others in another. Obviously, there must be some overlap (on keys). One idea is that of "attribute affinity" - a measure of the importance of two attributes appearing in the same partition. In 1984 Navathe et al developed an approach that incorporates transaction usage patterns to produce partitions of data [HEVN88].
Horizontal partitioning is based on predicates that define conditions on attribute values. It may be difficult to characterise the search space under certain conditions because attributes may take a wide range of value. Horizontal partitioning requires semantic understanding of data. Further work is required in this area, and to a certain extent this will be investigated in this research project.
Early placement models counted three basic costs; storage, retrieval, update. There is an important trade-off between retrieval and update costs. Retrieval cost is minimised by placing copies at every site, whereas update cost is minimised by having only one copy at an optimal site.
Other models consider both data and programs for placement, and hardware dependency (eg link capacity, storage costs).
Data dependency models consider the "affinity" of data files is how often they are accessed together. The Loomis & Popek [HEVN88] model of 1978 allows for parallelism. If files have a high probability of being accessed in the same request, they should be in different sites, to improve the potential parallelism. This is similar in concept to attribute affinity for vertical partitioning, described above.
Hanson and Orooji [HANS87] mention two other placement strategies in connection with multi-computer systems; round-robin, and Value Range Partitioning (VRP). Round-robin placement simply means that tuples of a relation are placed on different storage elements in a sequential manner. Parallelism is not guaranteed. VRP is the placement of tuples of horizontal relation partitions in a round-robin fashion.
The advantages of data replication are reliability, availability, and parallelism. Disadvantages are the difficulties involved in concurrency control, recovery, integrity, and security. These costs and benefits are hard to evaluate.
The two extreme strategies are no replication, and total replication. Most allocation strategies will want to provide designs in the middle. A general guideline is that a replication strategy should replicate data that is critical for reliability, or has high retrieval requirements from many sites. Highly sensitive, or frequently updated data should not be replicated.
This follows from data replication. So far, only static partitioning, placement, and replication has been considered. However, models have been developed which allow for the movement of data over time (file, or data, migration). The problems of dynamic data allocation in distributed systems are complex. The model by Laning & Leonard (1983), discussed in [HEVN88], proposes a method of dynamically monitoring the delay characteristics of a network. If performance falls to an unacceptable level due to poor placement strategy, a set of 'migration rules' is triggered. These cause data to be moved to other locations, with the intention of reducing the delays in the system.
Two types of user may be recognised, global, and local. The former processes data under the control of a DDBMS, and the local (nodal) user processes data under the control of the Nodal Database Management System (NDBMS) [DEEN84]. There are therefore two levels of control in a DDB, and their relationship affects the performance and nodal autonomy in a DDB. Global control can be either centralised or decentralised.
If control is centralised then all global processing is controlled by one node. Bottlenecks can result, and the system is vulnerable to communications breakdown. However preservation of consistency is simplified. With decentralised control, each node keeps a copy of the DBMS. The overall system is more reliable, but control and consistency are more difficult.
A related problem in a decentralised system is the maintenance of the dictionary. According to Deen, there are two options - a central directory copied at each node, or a number of directories each containing a subset of all entries at the appropriate nodes.
Blakey, however, mentions another option - an uninformed system, where data location is found by broadcasting requests to a central directory [BLAK87]. Leong-Hong and Plagman offer four metadata coordinating options: centralised, distributed replicated, distributed partitioned, hierarchy - (localised and centralised in a master/ slave relationship) [LEON82]. They suggest that the hierarchical option is viable, but theirs is a cursory overview, rather than a detailed analysis, or proposal.
Chu (1976) [HEVN88] studies the placement of directories on a distributed system, and concludes that distributing copies to all sites has a lower cost than a centralised directory, if a directory has a low update rate (which it should have). Blakey suggests that this type of placement has problems: unreasonable storage burden on small sites; network congestion due to dictionary updates; a user may know the location of an object that is subject to access control.
Blakey's arguments seem weak:
Note that the first two counter-arguments may not be true for the DRAT dictionary, due to its control of resources, but this is not the context within which Blakey puts forward his arguments. He proposes a partially informed distributed data base (PIDDB), which also contains a "knowledge model" which knows of other sites and objects. Any site is only aware of a subset of the system. This appears to be an enhancement of Deen's second option, or the distributed partitioned option of Leong-Hong & Plagman Some of the foregoing arguments are not relevant to DRAT, as the Dictionary will reside on one node, and control of the system will be centralised.
A detailed discussion of privacy is irrelevant to this report. Suffice to say that it is controlled by the DD.
There are three types of integrity: semantic, interprocess, internodal. Interprocess integrity (concurrency, or internal consistency) is usually tackled by the NDBMS. Control of interprocess integrity is an expensive operation in a decentralised DDB. Two phase commit is often used for this.
Communication link failure poses the greatest threat to reliability. Adequate backup and recovery is vital. One aspect of backup data replication - has been described in detail above.
A "heterogeneous network has different implementations of its components at each of its nodes", and a "homogeneous network is one where each node has the same hardware and software components" [LEON82].
Nodes may have different hardware, software, data models, languages, and concurrency control techniques. The classical solution is to define a "pivot" which is a canonical reference used to establish protocols, in order for nodes to communicate.
The issues involved in heterogeneity management are not relevant to DRAT.
Some of the concepts involved in distributed DBs, such as those outlined under User Facility, are applicable to both general purpose computers used for data processing, and for special purpose DB machines. Models that have been developed for distributed databases could be useful for a multi-processor database machine, although they would need to be tailored to suit the particular environment.
However, many problems have no parallels, for example, dollar communication costs, and heterogeneity problems, are not applicable to DRAT. If DRAT were to be used in a distributed environment, then, of course, these would need to be considered; but still, they would not be problems of the DRAT machine itself, but general problems associated with any machine in a distributed environment.
The most useful information that can be gleaned from the distributed database environment, and applied to DRAT, is under the heading of User Facility - ie data partitioning, placement, replication, and allocation.
A catalog contains metadata, specifically descriptors of tables, views, authorisation, schemata, etc. A data dictionary also contains metadata, but it may contain more than just descriptions of objects (for example, which departments receive which reports, design decisions, etc.) A combined data dictionary/catalog which is accessed by both the DBMS and users is an active data dictionary. A dictionary accessed by users/DBA only is passive. DRAT uses an active data dictionary.
A data dictionary should not be confused with a dictionary (or sometimes, dictionary machine), which is a data structure used for sorting and searching, and which supports instructions such as INSERT, DELETE, MEMBER [LI90, GOYA88].
One of the uses of an active data dictionary is to provide a control mechanism for the DBMS, in order to determine things such as user authorisation, view definitions, and data location information. In the DRAT architecture the dictionary also controls processor operations and data communications with respect to the relational operations that are to be carried out [KERR87, KERR88].
The problems of data dictionary maintenance and placement in distributed databases are outlined in 2.2.2 Multilevel Controls.
Although there are many references in the literature to data dictionaries, there is a paucity of detailed information on active data dictionaries.
Full details of the requirements of the DRAT data dictionary are given in chapter 3, Research Aims.
Contents | 1 Introduction | 2 Review | 3 Research aims | 4 Program | 5 Work | References | Appendix A | Appendix B | Appendix C