![Fig 3.1 Logical multi-processor database designs (diagram after [DEWI92])](images/fig3_1.gif)
If told of a potato peeling machine he will say it's impossible. If shown to peel a potato, he will complain because it will not slice a pineapple. [MFU 2020-11-03: This quotation is not correct. Refer to https://www.oxfordreference.com/view/10.1093/acref/9780191826719.001.0001/q-oro-ed4-00000632.]
Charles Babbage.
The aim of this chapter is to relate the business problem being addressed (i.e. the wish to run concurrent MIS queries against a Transaction Processing database) to the underlying architecture of the IDIOMS [KERR91a] machine. By doing this, it is possible to show that the overall problem can be split into two orthogonal problems, even at the physical level. By a comparison of IDIOMS with other multi-processor database machines the solutions presented later are shown to be applicable not only to IDIOMS, but also to any database machine which follows the "shared nothing" model of multi-processor database machines.
The structure of the chapter is as follows. This chapter commences with an overview of database machines in order to gain a global perspective. Then IDIOMS is described, and the problem is described with respect to the architecture. An example of dataflow principles is shown. Finally, more comparisons (i.e. in addition to those of chapter two) between IDIOMS and other multi-processor database machines are made, with a focus on the problem of concurrent OLTP/MIS and its solution.
In a recent excellent overview of the current state of parallel database systems DeWitt and Gray wrote, "In retrospect, special-purpose database machines have indeed failed; but parallel database systems are a big success" [DEWI92]. Taken out of context this appears a contentious point, but what they meant, as is clearly stated in other parts of their paper, is that specialised hardware solutions (e.g. associative memory devices, head-per-track storage devices) have not lived up to expectations. With this the author agrees.
"Much early work on database machines attempted to address problems through the use of specialised hardware solutions, in contrast to recent work which tends to favour the use of commercially available components. We could say that specialised hardware solutions are physical implementations of database machine concepts…, whereas the use of standard components leads to, in effect, a logical implementation (by means of software) of DB concepts (eg DRAT [a fore-runner of IDIOMS]). In the short term, the latter approach is more likely to lead to commercially viable products; there need not be any conflict with longer term developments of hardware based solutions" [UNWA91].
However, since IDIOMS is physically a single box, and since other workers also use the term "machine" rather than "system", it is convenient to continue in this vein. As Yao et al. have stated, "A database machine can be defined as a specialised software/hardware configuration designed to manage a database system" [YAO87]. Whether or not the hardware is special purpose is immaterial, although the current thinking is indeed that the use of off-the-shelf components is one of the reasons for the success of database machines/systems [DEWI92].
In the past, different taxonomies for database machines have been presented [SU88, QADA85, HURS89]. Su [SU88], for example, discusses database machines under the following categories:
Intelligent secondary storage devices
Database filters
Multi-processor database computers
Associative memory systems
Text processors
Su's classification is not tidy. The overall functionality of intelligent secondary storage devices and database filters is identical. According to Su, both use specialised hardware, but in different locations. No mention is made of purely software approaches which use standard components to achieve the required functionality, which is the IDIOMS approach. Additionally, IDIOMS has both distribution and replication of functions, which does not fit neatly into Su's classification.
As far as multi-processor database machines are concerned, it is now generally accepted that there are three basic forms, namely shared-nothing, shared-disc, and shared-everything [DEWI92, STON86]. These are shown in figure 3.1. The Teradata DBC/1012 [REED90], Gamma [GHAN90a, DEWI90a], Bubba [COPE88, BORA90], and IDIOMS [KERR91a] machines are based on the shared-nothing paradigm.
All these machines use the relational model, and hence queries can be described in terms of dataflow graphs [DEWI92]. Because these machines have many processors, it is possible to assign one or more nodes (strictly, the process which is the physical implementation of the node) of the graph onto different processors, thus allowing both pipelined parallelism, in which the output of one node is the input of another, and data parallelism, in which identical logical operations are carried out concurrently on different fragments of data. This is exemplified later in the section detailing IDIOMS. One further type of parallelism is independent task execution, in other words, different processors execute different tasks, thus allowing concurrent queries. Although this is not shown, IDIOMS is designed to cater for concurrent multiple OLTP transactions and multiple MIS queries.
IDIOMS [KERR91a] is a multi-processor database machine based on transputers [INMO88a], and on an abstract level is similar to both Bubba [COPE88] and Gamma [GHAN90a]. Figure 3.2 shows a schematic outline. The machine is designed to support relational databases of the order of 250 Gbyte. A demonstration version (900 Mbyte total storage capacity) using 9 OLTP storage and 3 relational processors (there were no MIS storage discs) has recently passed its performance tests [ENGL92].
The major aim of IDIOMS is to service both OLTP and MIS queries concurrently, even for complex MIS queries. Thus there are two sets of discs, one reserved specifically to store OLTP data and the other for MIS data such as summary tables, resulting in minimal interference between OLTP transactions and the access of purely MIS data. The design ensures that the OLTP discs have spare access capacity, which is used by MIS queries that require access to OLTP data. Although OLTP discs can be read by MIS, OLTP transactions have priority on disc access. OLTP transactions can be accessing one set of discs, while MIS queries requiring only MIS data are accessing another set.
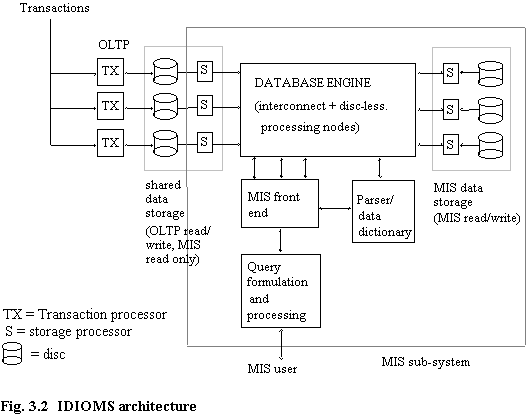
The underlying design principle of the IDIOMS machine is that of taking a parsed query tree and using it to construct a dataflow graph where the nodes specify the operations to be undertaken. Figure 3.6 is a schematic of the machine which shows just those parts pertaining to the flow of data for MIS queries. The basic architecture consists of storage processors and associated discs, relational processors, and a communications ring. Storage processors (S) are of two types, those that hold OLTP data, and those that hold MIS data, e.g. summary tables. OLTP discs are connected to transaction processors, which service OLTP queries. Currently each table or partition that is stored on disc has an associated Table Handler that implements SQL statements (select, update, insert, delete). The Table Handler process can be considered a specialised distributed file server. There are specific processes to deal with referential constraint processing and selections that refer to a column which has a unique constraint. Each Relational (R) processor has two associated input buffers, labelled B0 and B1, and an associated Insert (I) processor which is used to send intermediate results back to the communications ring.
The Parser/Data Dictionary (P/DD) is the heart of the control mechanism of IDIOMS, and consists of a set of processes and data structures (SQL tables).
The parser/data dictionary process consists of sub-processes, viz. parser, data dictionary, query optimiser/allocator. All of these are logically separate, although they interact closely. The Parser takes an MIS query in textual form, parses and validates it, and an internal representation is generated. The query optimiser/allocator requests information from the Data Dictionary, and uses this to generate the 'best' access plan [MURR91], considering the processing resource available, partitioning, and heuristics on previous hit rates of queries.
The basic required functions of the Data Dictionary (DD) are to:
In order to do this, a set of tables, which are an extension of SQL catalogue tables, are used. Of particular importance with respect to control flow in pipelined MIS queries are the Resource Control tables. These contain all the information necessary to control the flow of data for all the MIS queries; input and output ports for each operator, operations to be done on the various relational processors, inter- and intra- query sequencing. Thus the tables have some correspondence to the split and merge tables described by DeWitt [DEWI90b]. As far as the work presented in this thesis is concerned, the details of the SQL Catalogue Extension tables are unnecessary - the interested reader is referred to [UNWA92] for a full treatment.
The range partitioning approach to assignment of records to partitions is now justified, and an explanation of why this does not lead to complex placement or load balancing problems is given. Chapter 2 discusses the concepts of partitioning and placement in detail.
An analysis of transaction types used by the industrial collaborators in the IDIOMS project is helpful in understanding the file partitioning strategy. From their 300 or so different OLTP transactions we find that most (99.7%) use either account number or customer number (i.e. primary key) as the access key. The remaining 0.3% of transactions, namely "new account" and "new customer" by definition do not have an access key, as they are insertions of new records. A single key dense index is therefore appropriate to support OLTP transactions.
The basic considerations and assumptions regarding the OLTP system that IDIOMS is designed for are:
The first three points need no justification.
The assumption of some workers is that "the probability that a record is accessed in a given time period depends on some property of the record itself…" [CERI82]. This is often true as far as MIS is concerned. For OLTP it does not hold - the access frequency to a customer record is clearly determined by the habits of the customer; there are no a priori methods to determine this, although such things as age or income may have a partial influence. Although individual records within partitions will be accessed at greatly varying rates, due to the large size of the partitions, the aggregate rate of access will be, for all practical purposes, identical over the partitions.
Although the fifth assumption is frequently broken [DATE90], inasmuch as, for example, the type of account may be encoded within the account number, we are able to overcome this difficulty by ignoring (for the purposes of OLTP partitioning) those parts of the primary key that are not randomly generated.
Given that for OLTP data all the discs are of the same capacity and speed, the final assumption, in conjunction with the others, means that a complex allocation strategy that takes into account varying capacities and speeds of discs, or the relative heats of relations or partitions is not needed. The optimum OLTP strategy will be one that for each OLTP relation produces OLTP partitions containing equal numbers of tuples, the number of partitions being equal to the number of transaction processors.
Currently, a simple range partitioning strategy is used, where each relation is partitioned on the basis of the primary key of that relation (e.g. account number, policy number).
Provided OLTP transactions are not unduly hindered, nothing precludes further partitioning of data to aid MIS queries. As discussed in chapter two, round-robin, hash, and VRP (value range partitioning) all destroy locality of reference, and can be used to balance access frequency to partitions. For our purposes they confer no OLTP advantages, since the access frequency to tuples is random. From the standpoint of MIS these three strategies are often a hindrance. For range queries, range partitioning is the best strategy, since the others would require access to all partitions. For equality comparisons either range or hash partitioning can be used to advantage, but round robin and VRP result in access to all partitions. Range partitioning can aid some other scalar comparisons, (<, ≤, >, ≥) whereas once again the other strategies would require access to the complete relation.
Consider an artificially simple file for a banking database which contains customer data, which is partitioned on the basis of gender and age to aid MIS queries (figure 3.3).
CUSTOMER( C_NO, BRANCH, INITIAL, LASTNAME, ADDR_L1, ADDR_L2, CITY, POSTCODE, AGE, GENDER)
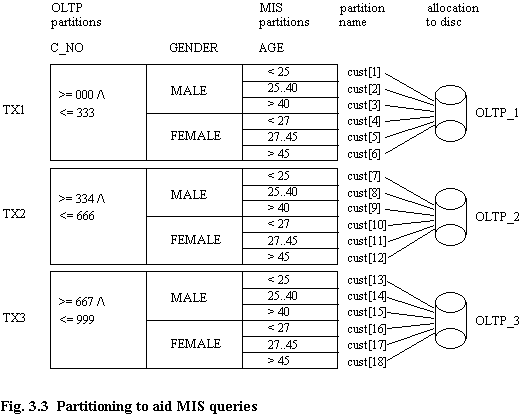
The primary key is C_NO (customer number). In many databases age would be calculated from date of birth, rather than there being a specific field for this. For convenience of exposition, it is much simpler to use age rather than date of birth, and hence this has been done. However, it is worth mentioning that the TSB database does indeed contain some tables in which an "AGE" column exists.
Let us assume that three Transaction Processors are needed to service the OLTP transactions - this means that there must be at least three physical OLTP partitions which can be accessed independently. In order to guarantee an even access rate for OLTP, we ensure that each of the OLTP partitions is of approximately equal size by selecting the partitioning boundary values on the basis of data distribution (for clarity, partitioning on the basis of 3 randomly generated digits in the customer number is assumed). Assume that by partitioning on the columns AGE and GENDER the data volumes accessed by MIS queries could be greatly reduced (see chapter 5 for discussion). Clearly, for gender there can be but two partitions, assuming that gender is always specified (i.e. a column cannot contain a NULL value). In practice, there may need to be a further partition to contain records for which some of the attribute values are not known.
Chapter 5 shows how for attributes which can have many data values, such as date of birth, the overall savings due to partitioning reduce asymptotically with the number of partitions. For convenience, the assumption that three date of birth (shown as AGE) partitions are appropriate has been made. The partition ranges for the attribute are shown as different for males and females, in order to exemplify how data skew is dealt with. The aim is to keep the cardinality of the sub-partitions approximately equal, so that MIS scan time of these is equal. However, even if the cardinality became unequal, this would not lead to any OLTP problems with different access rates to partitions, because what is important is the OLTP access rate to the Transaction Processing logical partitions. This is not affected by sub-partition cardinality inequalities, since the OLTP index spans all the sub-partitions.
Assume that one disc for each Transaction Processor is sufficient to store the OLTP partition of the CUSTOMER file and all the other files in the database. Although the assumption is unrealistic in practice, it is convenient for the purposes of explanation of dataflow principles.
In case more than one disc for each Transaction Processor is needed for storage requirements, each of the MIS partitions could be placed on a separate disc [UNWA92]. This is feasible and reasonable when the number of partitions is small. However, a more general solution is needed when there may be hundreds or thousands of partitions. The author's new proposal is that a simple strategy of round robin placement of MIS partition data to disc would guarantee MIS load balancing within and across each Transaction Processor disc set. This round robin placement of records should not be confused with either Ghandeharizadeh's round robin allocation of partitions in the HRPS [GHAN90b] or VRP, where data from each partition is placed on all available discs; here the placement is restricted to the disc set associated with the Transaction Processor. Apart from the trivially small start-up cost of the scanning process (i.e. < 1 microsecond) and the seek and rotational latency times (both very small with respect to partition scan time) to move the disc head to the partition, this would not affect in any way the determination of the total scan time of MIS partitions (chapter 5), nor would it affect the cost penalty of partitioning, since no migrations between these disc partitions would take place (figure 3.4). Of course, for very small relations in the case where there is more than one disc for each Transaction Processor due to total storage requirements, then it would be appropriate to consider the findings of Copeland [COPE88], and not allocate tuples of a partition over all these discs.
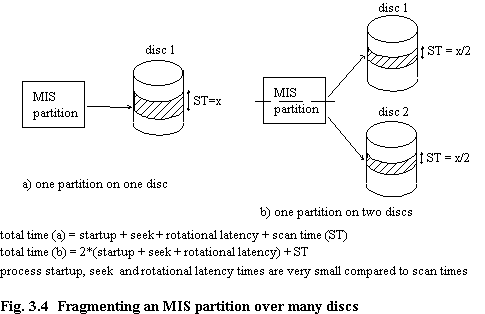
To summarise, there is an index on the primary key for each OLTP Transaction Processor partition, and space partitioning of each of these Transaction Processor partitions. The MIS partitions are of approximately equal cardinality (where possible), the partitioning predicates being chosen to achieve this.
For convenience, only the simplest of queries has been chosen to demonstrate dataflow principles. A more complex example can be found in [UNWA92]. Imagine that a pensions mailshot is to be targeted at all females between the ages of 20 and 30. The SQL query is:
SELECT C_NO, LASTNAME, ADDR_L1, ADDR_L2, CITY, POSTCODE
FROM CUSTOMER
WHERE GENDER = 'FEMALE' AND AGE >= 20 AND AGE <= 30
Figure 3.5 shows an access plan for this query, which is derived using the data dictionary's knowledge of partitioning. The access plan is based on the partitioning of figure 3.3, and for this reason the SELECT predicates of the plan superficially appear incomplete. This is not the case, as the partitioning forces an implicit predicate, and thus for example, partition cust[4] by definition contains only records for which age is less than 27 (and hence less than 30), and for which GENDER = 'FEMALE'.
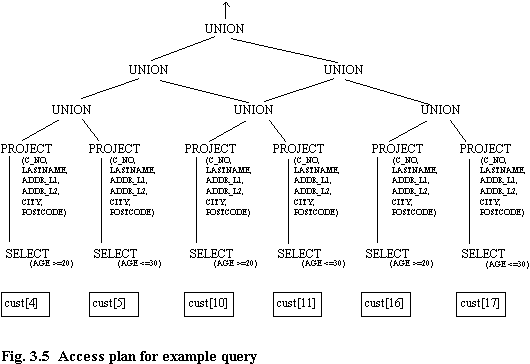
Figure 3.6 shows the flow of data round the machine. The relational processors used to service the query are determined using the Data Dictionary's knowledge of the overall resource availability. In this case, relational processors R1 and R2 and their associated input buffers and insert processors have been allocated to the query. The partitions are scanned, and the relevant rows and columns thereof are sent to the relational processors. As soon as data is available, processing can commence, so the union of records on R2 can begin as soon as records from R1 arrive at R2 (assuming of course that records from OLTP_1 have also arrived).
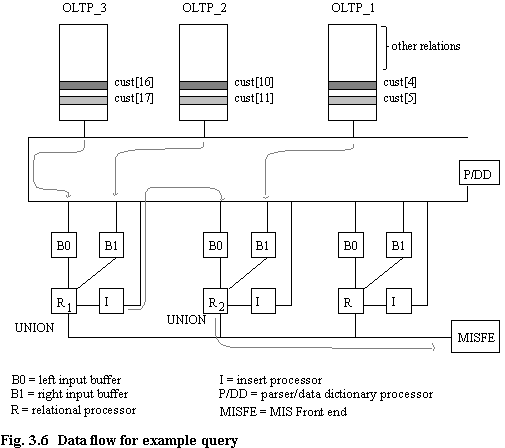
The reader can see from this example that by means of suitable partitioning, it is possible to reduce greatly the amount of data that must be scanned in order to answer an MIS query. Furthermore, by means of pipelining, the overall elapsed time to service a query can be reduced. Chapter 4 investigates the scan time and scan time savings between different numbers of partitions for columns which can have many data values (e.g. date of birth, surname, salary).
This section briefly compares three multi-processor database machines (Bubba, Gamma, Teradata DBC/1012) with IDIOMS, with attention being focused on aspects which have not been covered in chapter 2.
The Bubba parallel database system [BORA90] currently is implemented on a 40 node Flex/32 multicomputer, which is housed in 2 physically close cabinets. 32 nodes are used for the database machine itself, 4 nodes are used for software development and experiment control, and 4 nodes (2 in each cabinet) are used for inter-cabinet links. The nodes are connected by a common bus.
The first version of Gamma consisted of 9 VAX 11/750 computers each with 2 Mbyte of memory. A further VAX 11/750 acted as the host, and all the machines were connected by a token ring [GHAN90a]. Version 2 of Gamma is implemented on a 32 node iPSC/2 hypercube from Intel [DEWI90a], and thus Gamma is now physically closer to Bubba, DBC/1012 and IDIOMS.
The Teradata DBC/1012 [REED90], a successful commercial database machine, uses state of the art microprocessors (Intel 80286/80386 as of 1990). The interconnect is by means of the YNET, a proprietary configuration of communications processors.
At the interface between hardware and software lies (usually) an operating system. IDIOMS does not use a general purpose operating system, with additional processes tacked on to deal with functionality which is not provided by the operating system. This is justified in [KERR93b]. The functionality that is needed is obtained by means of specially written processes run directly on the transputers, and data partitioning and placement (i.e. top level file handling) is expressed by means of the DSDL [KERR91b]. The result is a "lean and mean" system.
Recall that a shared-nothing database machine consists of storage devices, processing elements, and an interconnection network. It is possible to combine the logical functions of processor nodes and storage nodes on the same device; the Bubba team do just this [BORA88, BORA90]. In other words, processes execute where the data resides. The advantage of reduced communications traffic is offset by the disadvantage that the processing power of the machine becomes dependent on the storage requirements and/or capability. With the IDIOMS design both the storage and the processing capacity can be scaled independently.
Unlike Bubba, where the global directory mechanism used to support declustering is replicated on storage processors [COPE88], IDIOMS' Parser/Data Dictionary is centralised because overall control is global. Furthermore, a replicated directory structure is not strictly scalable, since the size of each instance of the directory is proportional to the overall size (however measured) of the system. This, at least in theory, could become a problem.
Consider the Teradata machine, where each disc contains both MIS and OLTP data, with the result that "some DSU [disc] capacity must also be reserved for spool space for sorts" [REED90]. Clearly, this reserved space is wasted most of the time. Furthermore, this sharing of discs by OLTP and MIS data implies that while OLTP is reading/writing, MIS must wait, because there is only one physical disc arm on each disc. As stated previously, in IDIOMS there are two sets of discs, one reserved specifically to store OLTP data, and the other for MIS data, resulting in minimal interference between OLTP transactions and the access of MIS data.
Teradata has a partitioning strategy that is superficially similar to that of IDIOMS, in that "data in each DBC/1012 table is stored evenly across all AMPs [i.e. storage nodes]. This parallelism is, in fact one of the system's most significant benefits" [REED90]. However, Teradata choose a hybrid partitioning strategy based on the hashing of the primary key, whereas IDIOMS' data is range partitioned. The issues of partitioning strategies have already been discussed, the conclusion being that hash partitioning confers no advantages for the problem in hand.
The data partitioning of Gamma [GHAN90a] has some similarities to that of IDIOMS in that records of a file are randomly assigned (by hashing) to processors, and on each processor there is a dense index on the primary key. There is an additional clustering index on the column that is used for MIS type queries. Thus OLTP queries are directed to the appropriate processor, where the dense index ensures efficient retrieval. MIS queries are directed to all processors, and the clustering index enables a sequential scan to take place, the index itself being used to determine the extreme pages of the scan. The major flaw with this arrangement is that there can be only one clustering index, thus limiting efficient retrieval of range queries to those that specify the column which is indexed. Of course, this is not to criticise the method per se, it was chosen to study the effects of different partitioning and indexing strategies with respect to an MIS query set which accessed data on the basis of a singe column, rather than being chosen to aid MIS queries which reference many different columns. Ghandeharizadeh and DeWitt are right to conclude, "no partitioning strategy is superior under all circumstances. Rather, each partitioning strategy out-performs the others for certain query types".
Unlike some other workers [BRYA92, COPE88], and in spite of the considerations of chapter 2, no attempt is made to balance the access frequency of MIS queries to (OLTP) storage processors, for the following reasons.
With reference to partitioning of relations which are involved in operations which have a non-linear computation cost (e.g. join), the Bubba team state, "… we should identify the relations involved in this nonlinear operation (N-M join) and reduce their DegDecl [degree of declustering]" [COPE88]. Their reasoning is that message costs dominate, and are of the order O(DegDecl2). This is not the answer, since although message costs may be reduced by doing this, the problem is inherent in the operation i.e. an M-N join requires M×N comparisons. Indeed, in an attempt to overcome this, hash and range-partition based joins have been proposed e.g. [RICH89], [MISH92], where one logical join is physically implemented as a set of joins between partitions, and the results merged. Thus IDIOMS' multi-column partitioning for MIS range queries is likely to be beneficial for MIS joins, although much work is needed to quantify any benefits.
Boral states that data placement must be static because of the amounts of data involved [BORA88]. As far as allocation of space to partitions is concerned this is the approach taken with IDIOMS. However, the partitioning and placement strategy allows migration of data between partitions, with the constraint that the migration rate is low (refer to chapter 5).
To summarise, this chapter has shown how the architecture of a shared nothing multi-processor database machine allows the problem of concurrent access to a single data set by OLTP transactions and MIS queries can be solved (at least as far as the banking domain of IDIOMS' collaborators is concerned). Chapter 5 describes a cost model, and chapter 6 contains a worked example of the model. As a pre-requisite, we need to know how the number of partitions accessed by range queries (and hence scan time), varies with the size of queries - this is the subject of the following chapter.